

Содержание:
Представим, что ваше желание уволиться можно описать одним числом. Что будет влиять на него? Понятно, соответствие зарплаты ожиданиям. Потом — ваш комфорт в коллективе, адекватность руководителя. Расстояние до офиса, если вы ездите в офис, или до ЦОДа, если вы ездите в ЦОД, возраст, срок последнего повышения и так далее.
В этой модели всегда было слабое место — сложно посчитать совокупность влияния людей на вас. В целом-то всё просто: если вы работаете с теми, кто вам неприятен, то в зависимости от частоты взаимодействий желание уволиться растёт.
Следующий фактор: когда на новое место работы уходит кто-то, с кем вы сработались, ваш шанс на увольнение также резко растёт. Потому что он позовёт к себе — или потому что у вас уменьшится число людей, с кем вам было комфортно.
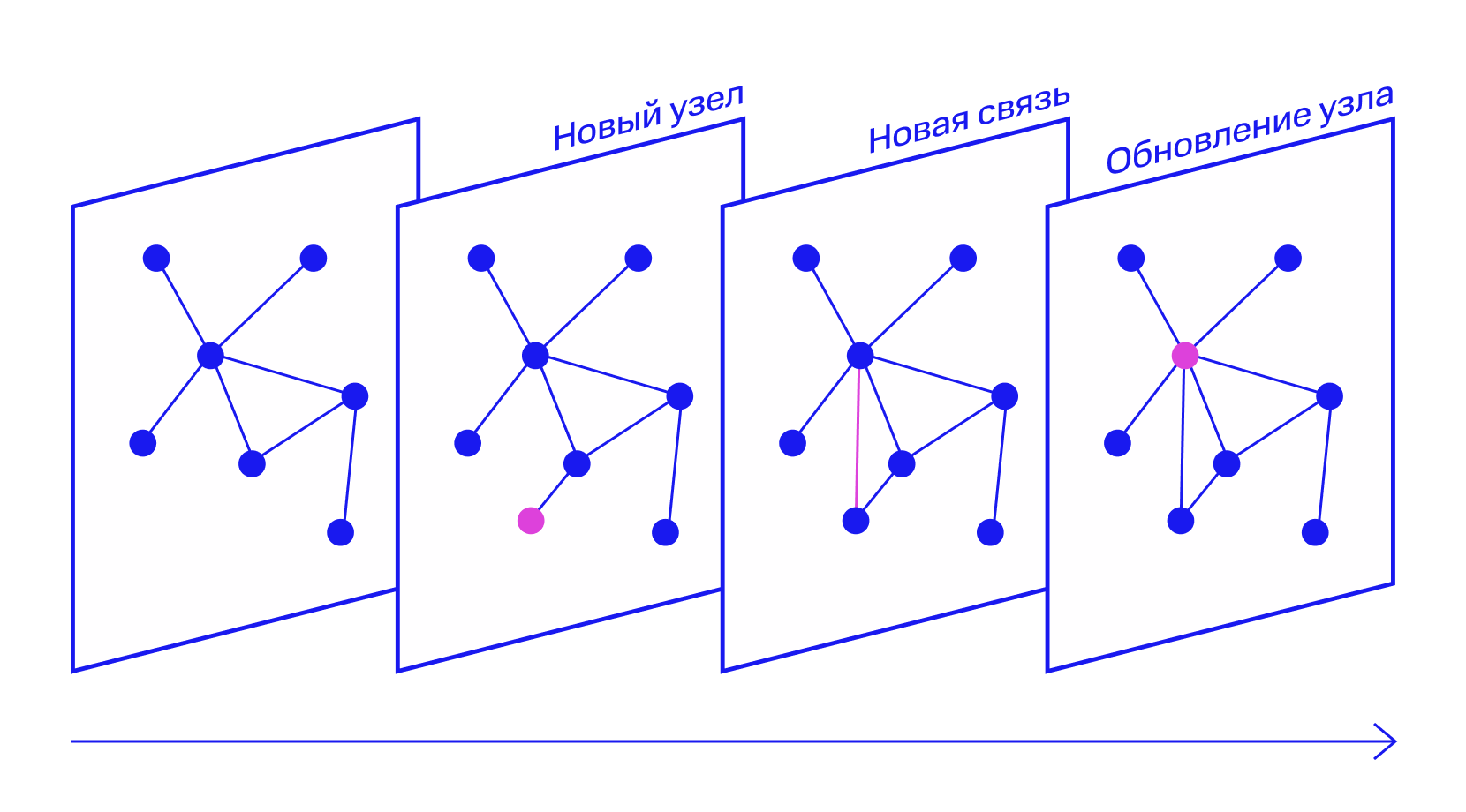
Мы не можем сказать, кто и с кем сработался. Таких источников данных у нас просто нет. Но мы сделали допущение о том, что если сотрудники плотно друг с другом взаимодействуют, то уход одного сотрудника увеличит вероятность ухода другого. И дальше на основании этого допущения составили граф всех сотрудников, в котором учли плотность взаимодействия между ними.
И знаете что? Наша модель начала предсказывать увольнения за 3 месяца с точностью около 70%. В смысле, из тех, кого модель разметила на месяц вперёд подтвердилось 73% случаев (точность), при этом модель находит 40% от всех увольнений (полнота).
Теперь мы можем с этим что-то делать.
Естественно, у этой модели огромное количество ограничений. Сейчас мы про всё это расскажем.
В этой модели всегда было слабое место — сложно посчитать совокупность влияния людей на вас. В целом-то всё просто: если вы работаете с теми, кто вам неприятен, то в зависимости от частоты взаимодействий желание уволиться растёт.
Следующий фактор: когда на новое место работы уходит кто-то, с кем вы сработались, ваш шанс на увольнение также резко растёт. Потому что он позовёт к себе — или потому что у вас уменьшится число людей, с кем вам было комфортно.
Мы не можем сказать, кто и с кем сработался. Таких источников данных у нас просто нет. Но мы сделали допущение о том, что если сотрудники плотно друг с другом взаимодействуют, то уход одного сотрудника увеличит вероятность ухода другого. И дальше на основании этого допущения составили граф всех сотрудников, в котором учли плотность взаимодействия между ними.
И знаете что? Наша модель начала предсказывать увольнения за 3 месяца с точностью около 70%. В смысле, из тех, кого модель разметила на месяц вперёд подтвердилось 73% случаев (точность), при этом модель находит 40% от всех увольнений (полнота).
Теперь мы можем с этим что-то делать.
Естественно, у этой модели огромное количество ограничений. Сейчас мы про всё это расскажем.

Что мы делаем
Мы занимаемся исследованием графов, имеем свой набор софта, и применяем свои матмодели для предсказания эффективности рекламных кампаний, для поиска источников обращений клиентов в розницу, для ряда задач на добывающих производствах — но собственный граф сотрудников тоже оказался отличным инструментом.
На входе у нас есть список сотрудников. Первая задача — найти такой источник, который поможет понять, кто с кем общается и каково влияние этих людей друг на друга.
У нас есть формальная иерархия. Она даёт первый набор данных: кто в каком отделе, кто у кого руководитель и так далее. Этого мало, потому что формальная иерархия никак не покрывает взаимоотношения между отделами. К счастью, их покрывает открытый (внутрикорпоративно) календарь встреч, который после эпохи удалёнки стал использоваться намного активнее. Встреч в курилках стало меньше, встреч онлайн больше. Он и даёт нам недостающие данные для понимания, кто с кем общается и как часто.
Я знаю, что в некоторых компаниях внедрён сбор данных с DLP, отслеживание корпоративных телефонов, BL-маячки для пропусков, мониторинг корпоративных мессенджеров, вычисление одновременных проходов по СКУДам и так далее, но это всё довольно мрачно. Да, это может повысить точность модели, но нам это не потребовалось. Мы ориентируемся на куда меньшее число данных, зато собираемых этично.
На входе у нас есть список сотрудников. Первая задача — найти такой источник, который поможет понять, кто с кем общается и каково влияние этих людей друг на друга.
У нас есть формальная иерархия. Она даёт первый набор данных: кто в каком отделе, кто у кого руководитель и так далее. Этого мало, потому что формальная иерархия никак не покрывает взаимоотношения между отделами. К счастью, их покрывает открытый (внутрикорпоративно) календарь встреч, который после эпохи удалёнки стал использоваться намного активнее. Встреч в курилках стало меньше, встреч онлайн больше. Он и даёт нам недостающие данные для понимания, кто с кем общается и как часто.
Я знаю, что в некоторых компаниях внедрён сбор данных с DLP, отслеживание корпоративных телефонов, BL-маячки для пропусков, мониторинг корпоративных мессенджеров, вычисление одновременных проходов по СКУДам и так далее, но это всё довольно мрачно. Да, это может повысить точность модели, но нам это не потребовалось. Мы ориентируемся на куда меньшее число данных, зато собираемых этично.
Выявление лидеров
Чтобы предсказывать увольнение (а это не единственное конечное применение), нужно выявлять лидеров. Фактически это даже не лидеры, а более или менее влиятельные люди для каждого конечного сотрудника. Но мы также выявляем лидеров в качестве промежуточной задачи.
Лидеры влияют на других людей существенно больше остальных. Они определяют микроклимат, работу с проблемами внутри процессов, взаимоподдержку.
С общечеловеческой точки зрения лидер — это тот, кто своим мнением или действием способен влиять на действия других людей. С позиции HR лидер — это руководитель. Мы исходили из неформального лидерства (фактического). Настоящий лидер может не обладать формальной властью, но при этом влиять на большое количество людей.
Лидеры влияют на других людей существенно больше остальных. Они определяют микроклимат, работу с проблемами внутри процессов, взаимоподдержку.
С общечеловеческой точки зрения лидер — это тот, кто своим мнением или действием способен влиять на действия других людей. С позиции HR лидер — это руководитель. Мы исходили из неформального лидерства (фактического). Настоящий лидер может не обладать формальной властью, но при этом влиять на большое количество людей.
Лидерами часто (но не обязательно) становятся те, кто важен в коллективе с точки зрения графа взаимодействий. Лидеры фактически перестраивают этот граф так, чтобы находиться в большом числе взаимодействий. Мы измеряем плотность коммуникаций между двумя сотрудниками, количество связей (со сколькими людьми взаимодействует сотрудник) и Katz centrality (центральность по Кацу).
Собственно, на берегу мы договорились, что я и другие сотрудники моей команды не могут посмотреть, кто с кем связан из сотрудников конкретно. Но можно получить числа влияния друг на друга в целом и посмотреть итоговый агрегат.
Датасет — 30 тысяч сотрудников за 2 года. Понятно, что не у всех полные 2 года, у кого-то меньше. Данные не очень глубокие, как видите, но их достаточно просто собрать практически в любой крупной компании. Датасет подразумевает обучение только по самостоятельным увольнениям, а не по увольнениям со стороны компании (например, за нарушения) и не такие случаи, как увольнение по причине пенсии или смерти.
Собственно, на берегу мы договорились, что я и другие сотрудники моей команды не могут посмотреть, кто с кем связан из сотрудников конкретно. Но можно получить числа влияния друг на друга в целом и посмотреть итоговый агрегат.
Датасет — 30 тысяч сотрудников за 2 года. Понятно, что не у всех полные 2 года, у кого-то меньше. Данные не очень глубокие, как видите, но их достаточно просто собрать практически в любой крупной компании. Датасет подразумевает обучение только по самостоятельным увольнениям, а не по увольнениям со стороны компании (например, за нарушения) и не такие случаи, как увольнение по причине пенсии или смерти.
Как это используется
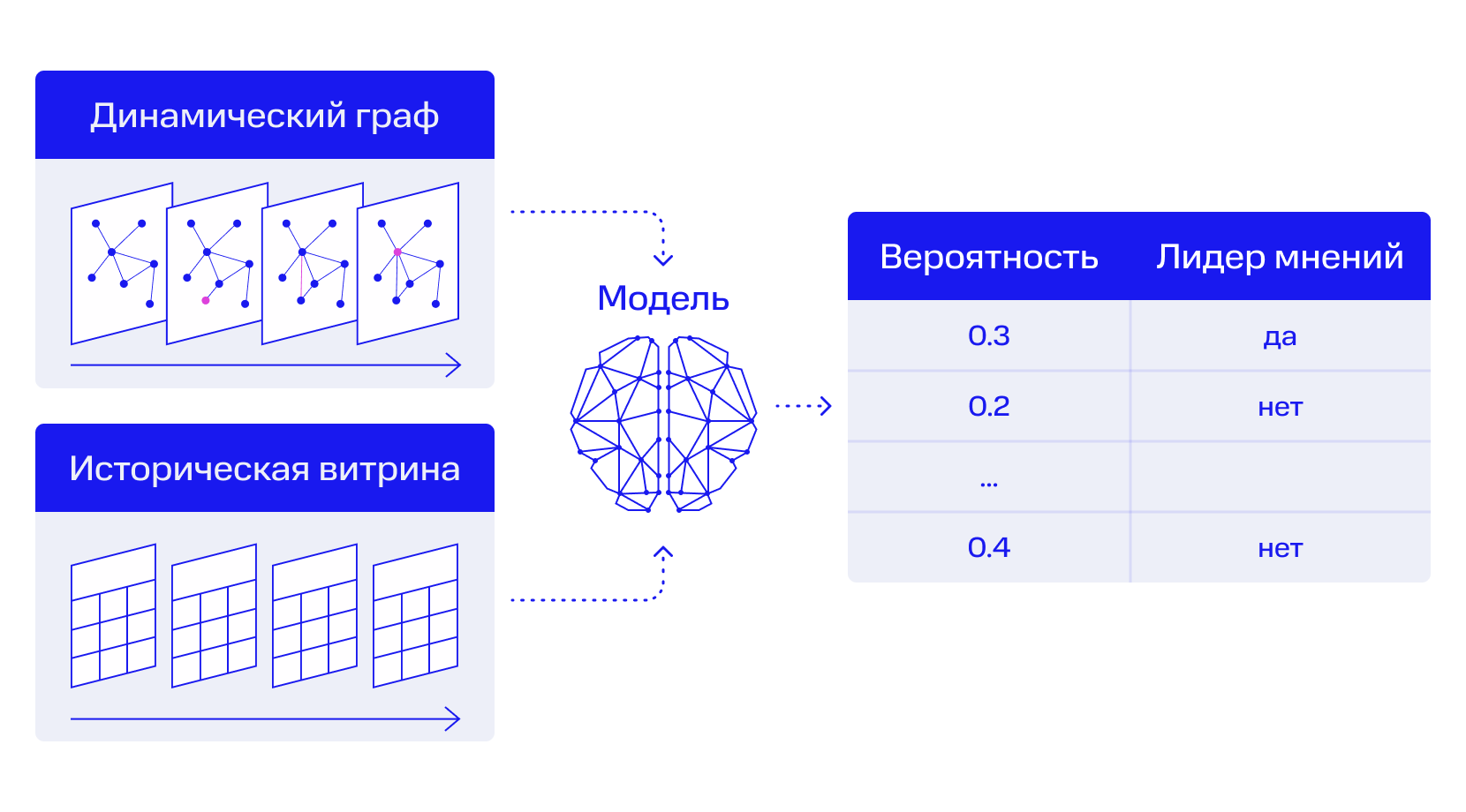
Есть историческая витрина на каждый месяц. У каждого сотрудника есть признаки, которые влияют на его желание работать или сменить работу.
Например, это расстояние от дома до офиса, зарплата, возраст, количество дней с последнего повышения, время работы итого, семейный статус (есть дети или нет), образование и так далее. Это, условно говоря, статические коэффициенты.
Например, это расстояние от дома до офиса, зарплата, возраст, количество дней с последнего повышения, время работы итого, семейный статус (есть дети или нет), образование и так далее. Это, условно говоря, статические коэффициенты.
Дальше есть граф взаимодействий внутри компании. Из него также высчитывается динамический коэффициент довольства. На первом проходе мы считаем статические коэффициенты для каждого, затем по графу взаимодействий передаём влияние желания и нежелания работать по этому самому графу на других сотрудников. Затем пересчитываем ещё раз уже для новых итоговых оценок у каждого. Это делает графовая нейросеть, агрегирующая особенности человека и соседей. При помощи графовых слоёв мы получаем эмбеддинг — представление каждого в векторном пространстве. Оттуда и делаем предсказание.
Получается индекс, который и является прогнозом увольнения. Мы выводим в разрезе на 1 месяц, 3 месяца и 6 месяцев. На 1 месяц предсказать сложнее всего, потому что человек долго «раскачивается». На 6 месяцев прогноз куда более точный. Речь про 70–80% точности.
Что получается
Мы знаем, с какой вероятностью вы уволитесь. Примерно, но знаем.
При увольнении сотрудника мы можем предсказать, кто будет увольняться за ним, и это поможет что-то поменять и удержать людей.
Для каждого сотрудника мы можем предположить, насколько его уход поменяет мнение других людей его графа общения — то есть сказать стоимость его увольнения, кроме прямых эффектов.
В итоге на практике:
При увольнении сотрудника мы можем предсказать, кто будет увольняться за ним, и это поможет что-то поменять и удержать людей.
Для каждого сотрудника мы можем предположить, насколько его уход поменяет мнение других людей его графа общения — то есть сказать стоимость его увольнения, кроме прямых эффектов.
В итоге на практике:
- Мы можем предсказать, когда захочет уволиться, например, руководитель отдела. Объективно, если он уже решил, то вряд ли мы с этим что-то сделаем, но…
- Мы можем предсказать, кто уволится после этого за ним или из-за изменившихся условий — и удержать уже их. То есть остановить волну увольнений после первого.
Дашборд со скорингом есть у кадров. Кадры могут связаться с руководителем «рискового» человека и предложить какие-то меры. Где-то помогает обучение, где-то напоминают про повышение, кому-то нужен отпуск уже давно, где-то нужно поднимать зарплату и так далее.
Кстати, далеко не всегда вопрос решается деньгами.
Это ассистирующая метрика, а не повод для окончательного решения. HR-отдел считает также свои метрики, но теперь иногда поглядывает и на эту.
В перспективе такая метрика даст возможность считать HR-влияние человека на компанию (к сильному известному в сфере человеку тянутся сильные сотрудники со всего рынка, и это стоит отдельных денег), решать конфликты (с оценкой, если двое поцапались навсегда, какие последствия будет означать для графа доминирование каждого), можно собирать продуктовые команды с новыми выявленными лидерами и так далее. Неформальные лидеры важны HR для разных процессов вроде комитетов изменений: если они будут на стороне новых внедрений, то они пройдут куда более гладко.
Кстати, далеко не всегда вопрос решается деньгами.
Это ассистирующая метрика, а не повод для окончательного решения. HR-отдел считает также свои метрики, но теперь иногда поглядывает и на эту.
В перспективе такая метрика даст возможность считать HR-влияние человека на компанию (к сильному известному в сфере человеку тянутся сильные сотрудники со всего рынка, и это стоит отдельных денег), решать конфликты (с оценкой, если двое поцапались навсегда, какие последствия будет означать для графа доминирование каждого), можно собирать продуктовые команды с новыми выявленными лидерами и так далее. Неформальные лидеры важны HR для разных процессов вроде комитетов изменений: если они будут на стороне новых внедрений, то они пройдут куда более гладко.








